Since my last Post about TIMA a few thing have happened and changed. We added and FAQ page, and most noticeably a we added a section with games to the Website. Currently there is only one: AssociationChain.
AssociationChain is a simple game in which you and TIMA build an association chain together. The rules are as follows: You and TIMA alternately associate a word to the previous association. The goal is to build long chains.
As for the Apps it's a work in progress. The basic functionally of the Website is in the App and works we'll see that rest get's into it an that we can distribute it. As for the game Apps that will take some more time.
As for the TIMA itself. We currently support four languages: German, English, Spanish and Farsi. We have a total of over 3400 words and over 4000 unique associations.
TIMA short for "TIMA is my association" is a citizen science project I currently work on. The goal of the project is to build a large database of associations. To get the associations we need your help. Everyone who want can go to our website and start. First you need to select a language and then you get a word and asked to type in your association of said word. For each association you will receive points and a new word.
Besides the website we are in the process of building some apps. The first and most basic app follows the design concept of the website and gives you words and asks for your associations. In a later phase we have plan for apps that will have a more game like approach. One will be based on the concept of the German TV-show Familien-Duell. I will write more to that in a later post.
In addition to the collection of association we also publish them. On the website is a list of all the words and their association with some graphs and statistics. We have also an extensive API, over which the data can be exported. In addition we have included OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting). This is a low-barrier mechanism the expose metadata for repositories. Our base URL is https://tima.jnphilipp.org/oai2/.
This is one of the website I mentioned in my previous post about Bootstrap. The website is written in Python using the Django web framework. You can checkout the code on GitHub.
I recently had to build a few website, about which I'll write soon a bit, in which I used Bootstrap. Since the design I used when I build this site was somewhat crude I started to do some redesigning using Bootstrap. The result of these efforts are now online. Enjoy!
I'm sorry I'm a little late with this, but I finally came around to write this post. In the last term I took a course were we had to write a simulated web crawler and implement different crawling strategies. The complete code and detailed descriptions on inputs and how to compile and run it are on GitHub.
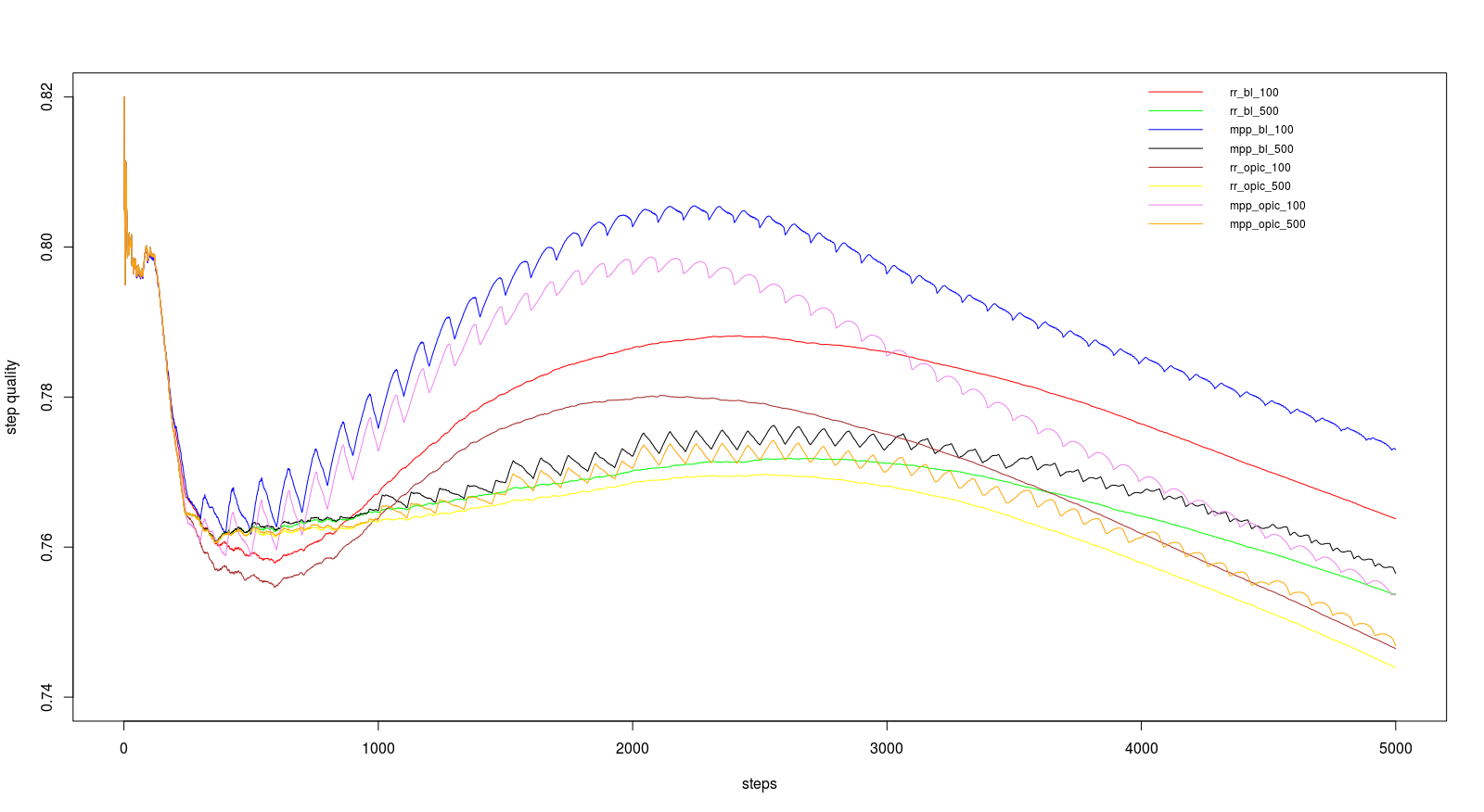
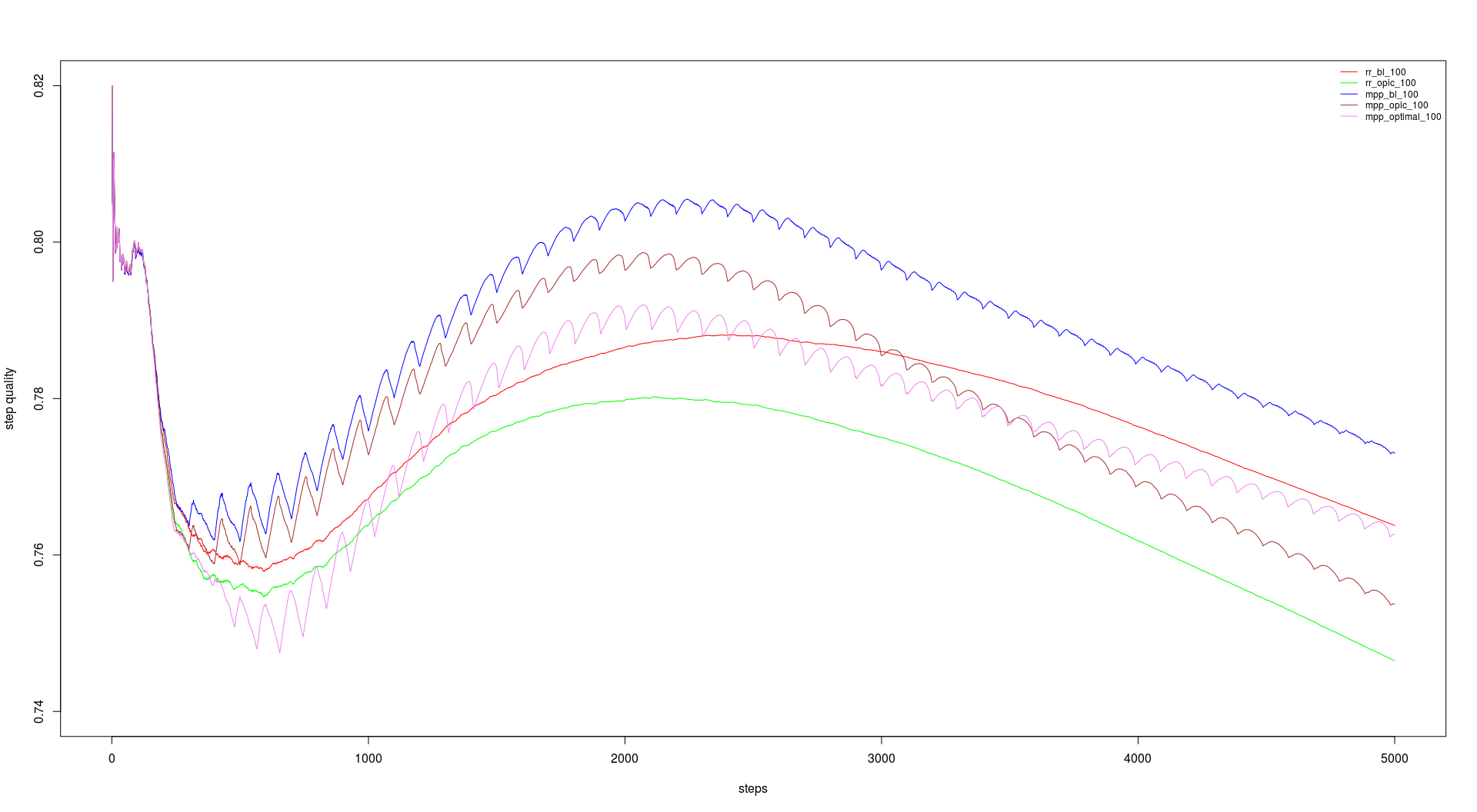
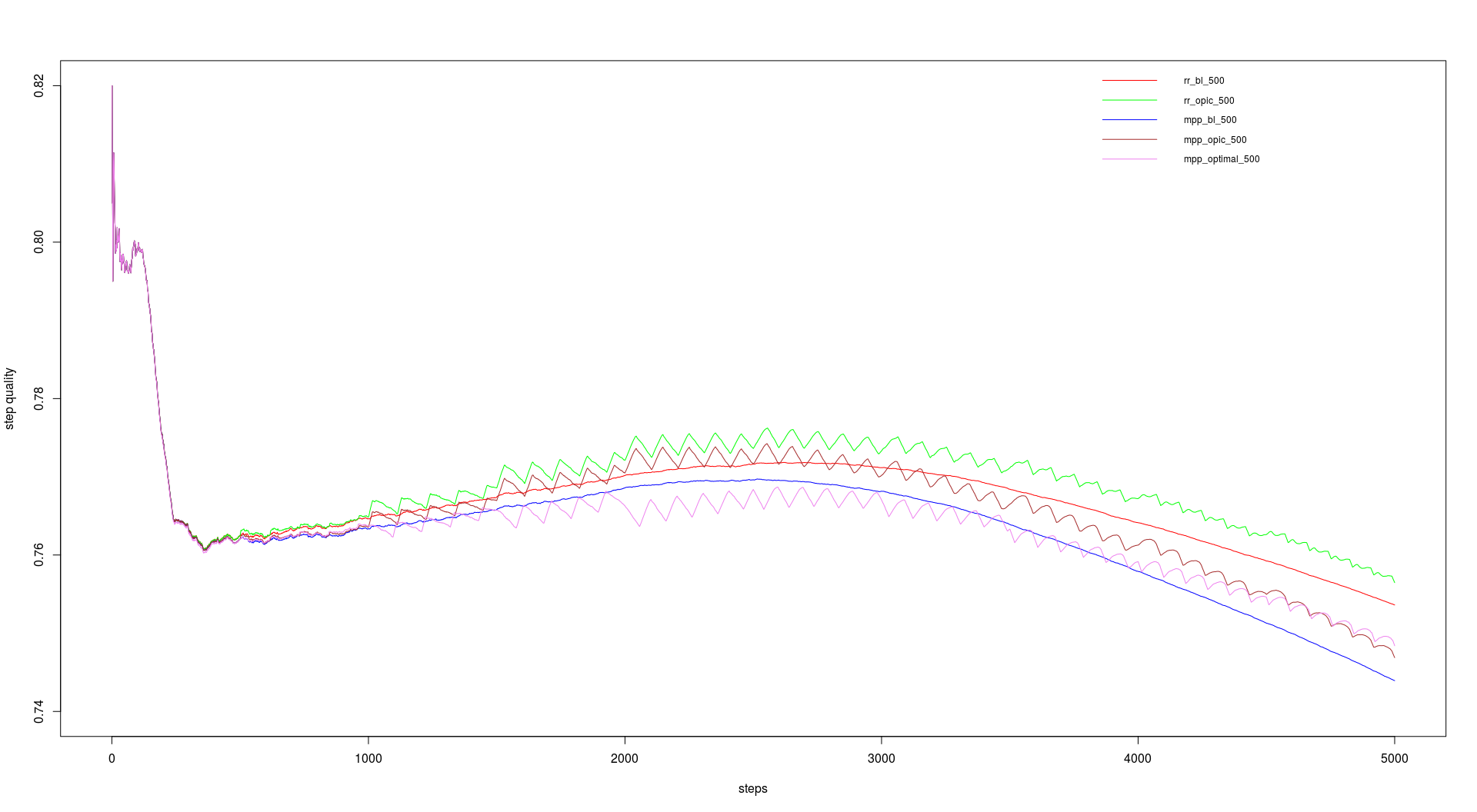
First we had to implement breadth-first search strategy and then two page level (backlink-count and OPIC) and two site level (round robin and max page-priority) strategies, which should be combianed as desired. And finally we should use OPIC, backlink-count and the ratio of good to bad pages to develop a formula to combine them to a strategy called OPTIMAl.
On the first run two input files need to be provided, the first on is the link graph and the second one the quality mapping. Bevor the actual crawling starts, the files will be read an stored in a MapDB for easy access. As long as the MapDB files exist there is no need to provide the link graph and quality mapping file. If they are provided the MapDB will be recreated.
For performance reason the crawling itself is done in threads via a ScheduledThreadPoolExecutor. A single thread performce the crawling of a single site.
For the course we had a link graph with about 230 million entries (including duplicates) on which we should run our tests. We should do 5000 steps with 200 URLs per step and a batch size of 100 and 500. The batch size dictates the update intervalls for backlink count and OPIC. The runtimes are in the table below and the performance in the graphs.
The last few weeks I worked with some people on a smart meter project. Our goal was to show how to receive the data on a large scale and to handle them. We divided it into three parts, the first was a generator for generating lifelike data. The second part was based on Apache Storm and Apache Accumulo received the data and stored them and the third part generated reports with Map Reduce.
Welcome to my new blog. It's been quite some time since my last blog. Back then I ran it on some old hardware I had. When it crashed I made a half hearted attempt on WordPress. Which quickly died down. Now I got a virtual server mainly to run some other projects. So I decided to start a new blog. Nothing fancy, just something to keep a record of my projects and ideas.