I'm sorry I'm a little late with this, but I finally came around to write this post. In the last term I took a course were we had to write a simulated web crawler and implement different crawling strategies. The complete code and detailed descriptions on inputs and how to compile and run it are on GitHub.
First we had to implement breadth-first search strategy and then two page level (backlink-count and OPIC) and two site level (round robin and max page-priority) strategies, which should be combianed as desired. And finally we should use OPIC, backlink-count and the ratio of good to bad pages to develop a formula to combine them to a strategy called OPTIMAl.
On the first run two input files need to be provided, the first on is the link graph and the second one the quality mapping. Bevor the actual crawling starts, the files will be read an stored in a MapDB for easy access. As long as the MapDB files exist there is no need to provide the link graph and quality mapping file. If they are provided the MapDB will be recreated.
For performance reason the crawling itself is done in threads via a ScheduledThreadPoolExecutor. A single thread performce the crawling of a single site.
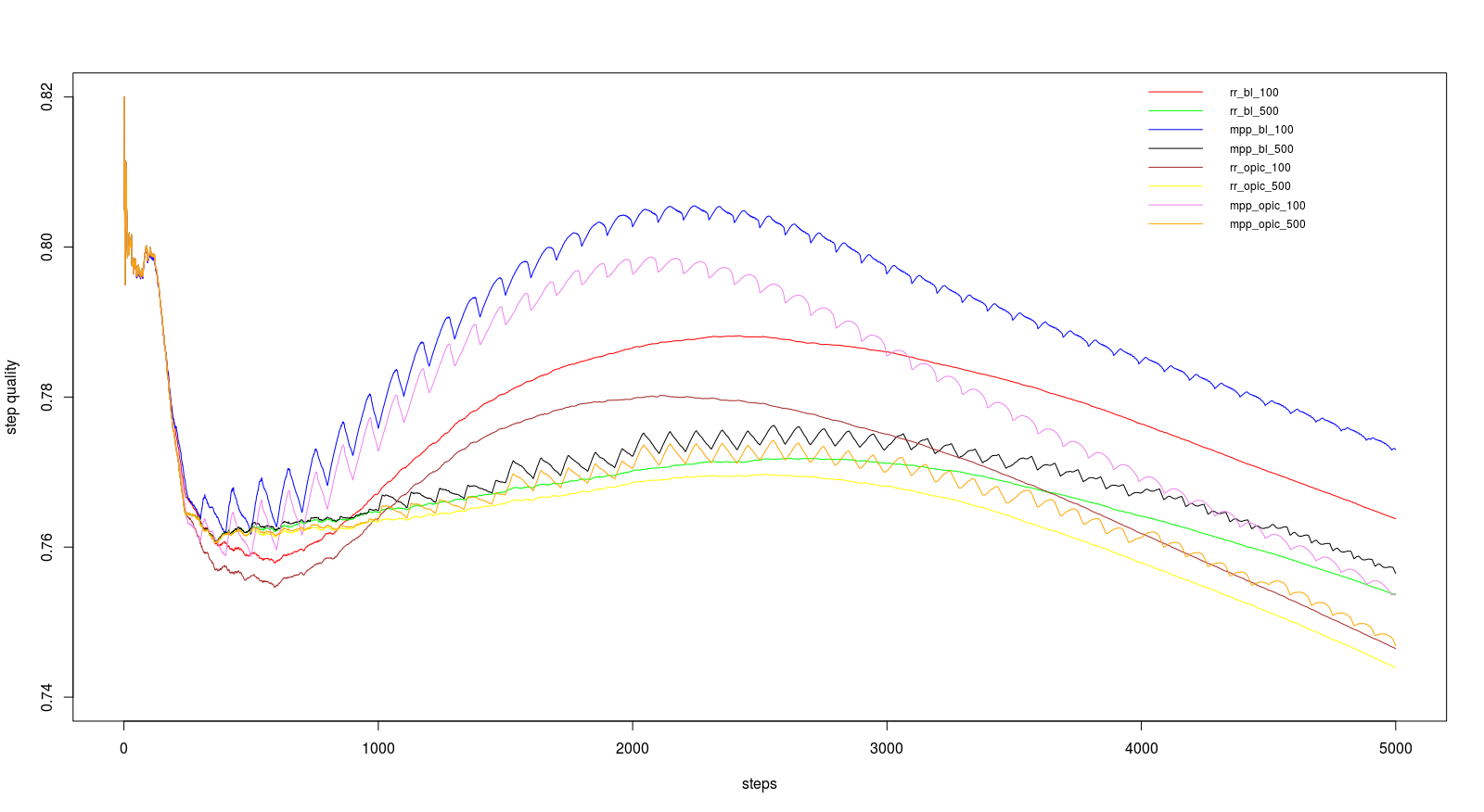
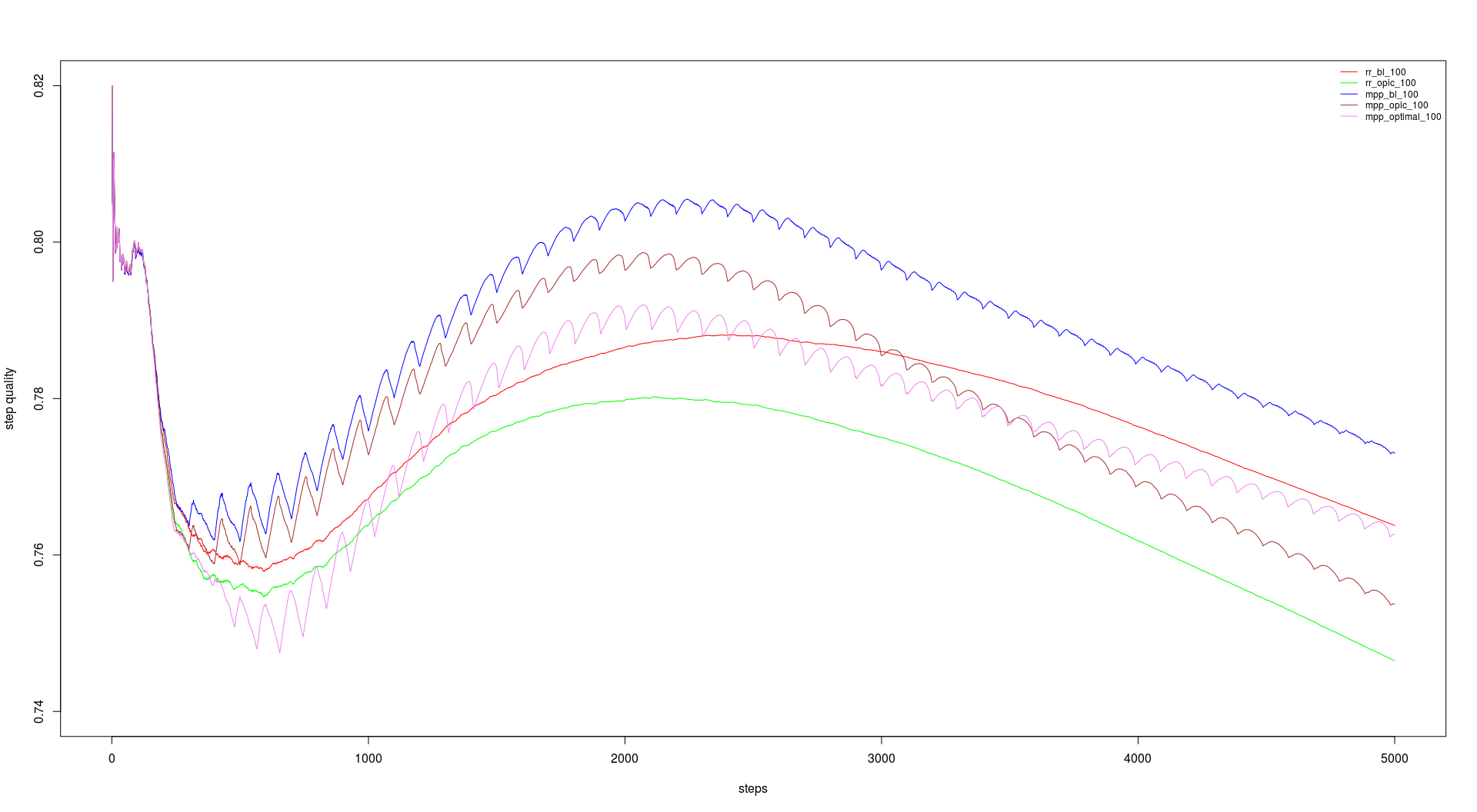
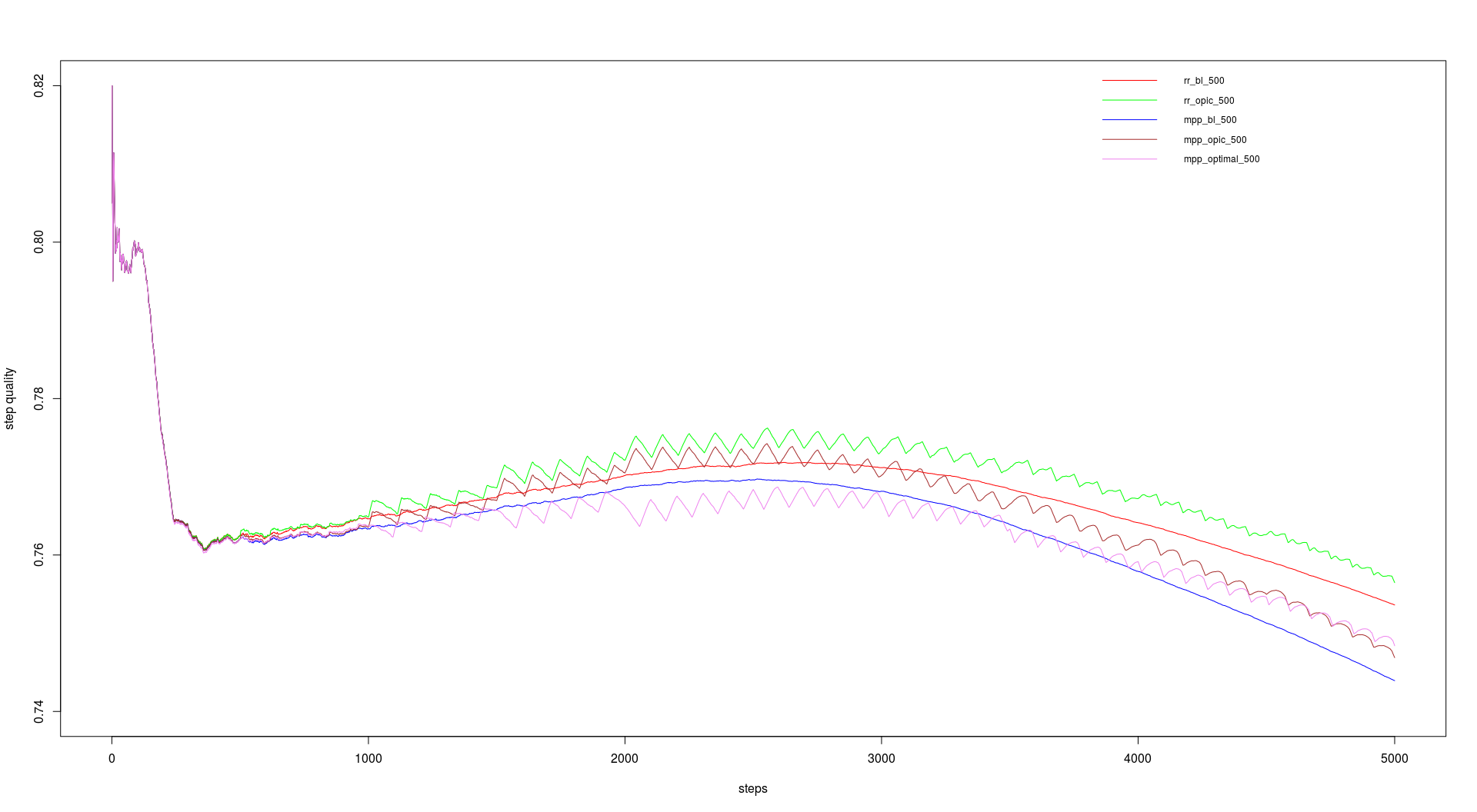
For the course we had a link graph with about 230 million entries (including duplicates) on which we should run our tests. We should do 5000 steps with 200 URLs per step and a batch size of 100 and 500. The batch size dictates the update intervalls for backlink count and OPIC. The runtimes are in the table below and the performance in the graphs.
- breath-first search: 1:11.241s
- round robin, backlink count, batch size: 100: 3:03.407s
- round robin, backlink count, batch size: 500: 2:59.153s
- round robin, OPIC, batch size: 100: 3:35.574s
- round robin, OPIC, batch size: 500: 3:06.375s
- max page priority, OPIC, batch size: 100: 3:30.296s
- max page priority, OPIC, batch size: 500: 3:03.940s
- max page priority, backlink count, batch size: 100: 3:14.608s
- max page priority, backlink count, batch size: 500: 2:17.481s